(转自:机器之心)生讯网
第一作者陈昌和是美国密歇根大学的研究生,师从 Nima Fazeli 教授,研究方向包括基础模型、机器人学习与具身人工智能,专注于机器人操控、物理交互与控制优化。
第二作者徐晓豪是美国密歇根大学机器人学院博士生,研究涵盖3D 感知、视觉语言模型驱动的多模态异常检测及鲁棒三维重建。
共同第一作者 Quantao Yang 是瑞典皇家理工学院博士后,师从 Olov Andersson 教授,研究聚焦于利用视觉语言模型与大型语言模型提升自主系统在动态环境中的感知与导航能力。
密歇根大学和瑞典皇家理工学院的研究团队提出了 ViSA-Flow 框架,这是一种革命性的机器人技能学习方法,能够从大规模人类视频中提取语义动作流,显著提升机器人在数据稀缺情况下的学习效率。该方法在 CALVIN 基准测试中表现卓越,仅使用 10% 的训练数据就超越了使用 100% 数据的现有最佳方法。

作者: Changhe Chen, Quantao Yang, Xiaohao Xu, Nima Fazeli, Olov Andersson
机构: 密歇根大学、瑞典皇家理工学院生讯网
网页: https://visaflow-web.github.io/ViSAFLOW
论文链接:https://arxiv.org/abs/2505.01288
代码开源: 即将发布
研究背景与挑战
机器人模仿学习在使机器人获得复杂操作技能方面取得了显著成功,但传统方法面临一个根本性限制:需要大量精心策划的机器人数据集生讯网,收集成本极其昂贵。这已成为开发能够执行多样化现实世界任务的机器人的关键瓶颈。
相比之下,人类展现出通过观察他人学习新技能的非凡能力。无论是面对面学习、观看教学视频还是体育转播,人类本能地专注于语义相关的组件。例如,学习网球时,我们自然地关注球员的身体动作、球拍处理技巧和球的轨迹,同时有效过滤无关的背景信息。
核心创新:语义动作流表示
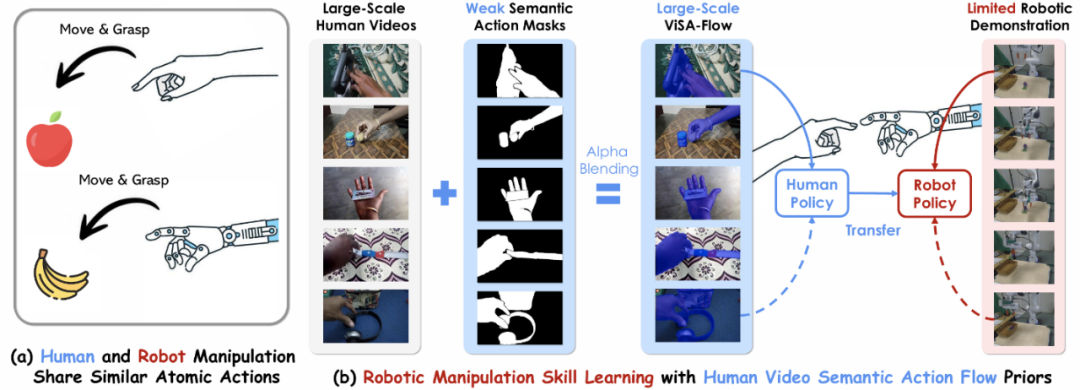 人类和机器人操作共享相似原子动作
人类和机器人操作共享相似原子动作ViSA-Flow 框架的核心创新在于引入了语义动作流(Semantic Action Flow)作为中间表示,捕捉操作器 - 物体交互的本质时空特征,且不受表面视觉差异影响。该框架包含以下关键组件:
1. 语义实体定位
利用预训练的视觉语言模型(VLM)对操作器(如 "手"、"夹具")和任务相关物体(如 "红色方块")进行文本描述定位,然后使用分割模型(如 SAM)生成初始分割掩码。
2. 手 - 物体交互跟踪
由于语义分割在连续帧间的不稳定性,研究团队提出跟踪正确分割的手 - 物体交互掩码。通过在初始掩码内密集采样点,使用点跟踪器(如 CoTracker)估计这些点在序列中的 2D 图像轨迹。
3. 流条件特征编码
为产生最终的 ViSA-Flow 表示,研究团队将流信息编码为丰富的特征向量,同时保留视觉上下文。使用跟踪点轨迹生成空间局部化放大掩码,通过放大因子调制感兴趣区域内的像素强度。
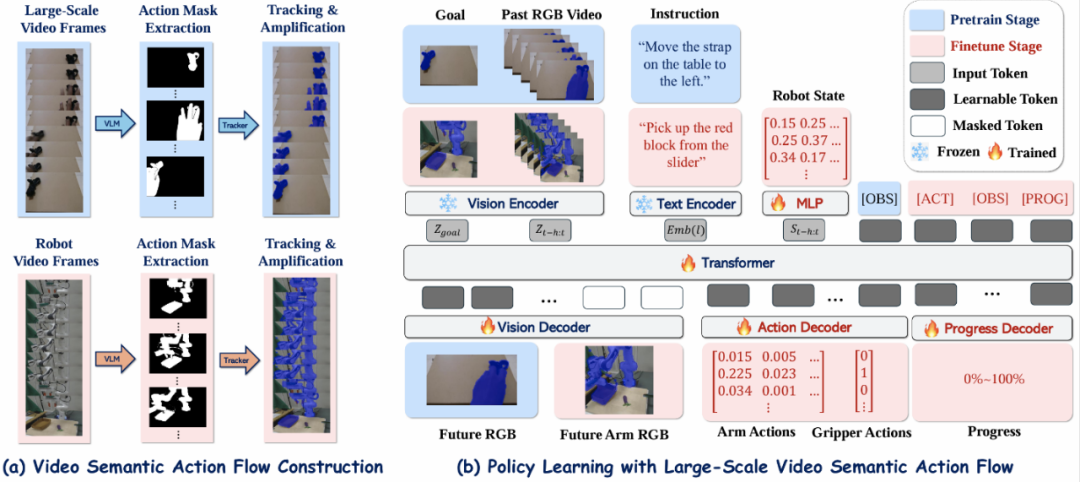 ViSA-Flow 架构和策略学习框架图
ViSA-Flow 架构和策略学习框架图两阶段学习框架
第一阶段:预训练 - 学习 ViSA-Flow 动态先验
使用大规模人类视频数据集,预训练生成模型以建模 ViSA-Flow 空间内的动态。模型学习基于过去上下文和语言指令预测未来表示,目标函数为:
L_pretrain (ψ) = E [生讯网
富灯网官网提示:文章来自网络,不代表本站观点。
相关文章



沪深京指数
热点资讯
